Оцінка значущості рівняння множинної регресії
Побудова емпіричного рівняння регресії є початковим етапом економетричного аналізу. Перше ж побудоване за вибіркою рівняння регресії дуже рідко є задовільний за тими чи іншими характеристиками. Тому наступною найважливішим завданнямЕконометричного аналізу є перевірка якості рівняння регресії. В економетриці прийнято усталену схему такої перевірки.
Отже, перевірка статистичної якості оціненого рівняння регресії проводиться за такими напрямками:
· Перевірка значущості рівняння регресії;
· Перевірка статистичної значимостікоефіцієнтів рівняння регресії;
· Перевірка властивостей даних, здійсненність яких передбачалася при оцінюванні рівняння (перевірка здійсненності передумов МНК).
Перевірка значущості рівняння множинної регресії, як і парної регресії, здійснюється з допомогою критерію Фішера. У разі (на відміну парної регресії) висувається нульова гіпотеза Н 0у тому, що це коефіцієнти регресії дорівнюють нулю ( b 1=0, b 2=0, … , b m=0). Критерій Фішера визначається за наступною формулою:
де Dфакт - факторна дисперсія, пояснена регресією, однією ступінь свободи; Dост - залишкова дисперсія однією ступінь свободи; R 2- Коефіцієнт множинної детермінації; т ху рівнянні регресії (у парній лінійної регресії т= 1); п -кількість спостережень.
Отримане значення F-критерію порівнюється з табличним за певного рівня значущості. Якщо його фактичне значення більше табличного, тоді гіпотеза Алепро незначущість рівняння регресії відкидається, і приймається альтернативна гіпотеза про його статистичній значущості.
За допомогою критерію Фішера можна оцінити значущість як рівняння регресії загалом, а й значимість додаткового включення у модель кожного чинника. Така оцінка необхідна для того, щоб не завантажувати модель факторами, які не суттєво впливають на результат. Крім того, оскільки модель складається з кількох факторів, то вони можуть вводитися в неї в різній послідовності, а так як між факторами існує кореляція, значимість включення в модель одного і того ж фактора може відрізнятися в залежності від послідовності введення в неї факторів.
Для оцінки значущості включення додаткового фактора у модель розраховується приватний критерій Фішера F xi.Він побудований на порівнянні приросту факторної дисперсії, обумовленого включенням до моделі додаткового фактора, з залишковою дисперсією на один ступінь свободи за регресією в цілому. Отже, формула розрахунку приватного F-критеріюдля фактора матиме наступний вигляд:
де R 2 yx 1 x 2… xi … xp -коефіцієнт множинної детермінації для моделі з повним набором пфакторів ; R 2 yx 1 x 2… x i -1 x i +1… xp- Коефіцієнт множинної детермінації для моделі, що не включає фактор x i;п- Число спостережень; т- Число параметрів при факторах xу рівнянні регресії.
Фактичне значення приватного критерію Фішера порівнюється з табличним при рівні значимості 0,05 або 0,1 та відповідних числах ступенів свободи. Якщо фактичне значення F xiперевищує F табл, то додаткове включення фактора x iмодель статистично виправдано, і коефіцієнт «чистої» регресії b iпри факторі x iстатистично значущий. Якщо ж F xiменше F табл, то додаткове включення до моделі фактора суттєво не збільшує частку поясненої варіації результату. у,і, отже, його включення до моделі немає сенсу, коефіцієнт регресії при цьому факторі у разі статистично незначимий.
За допомогою приватного критерію Фішера можна перевірити значущість усіх коефіцієнтів регресії у припущенні, що кожен відповідний фактор x iвводиться у рівняння множинної регресії останнім, проте інші чинники були вже включені в модель раніше.
Оцінка значимості коефіцієнтів «чистої» регресії b iпо критерію Стьюдента tможе бути проведена і без розрахунку приватних F-Критеріїв. У цьому випадку, як і за парної регресії, для кожного фактора застосовується формула
t bi = b i / m bi ,
де b i- Коефіцієнт «чистої» регресії при факторі x i ; m bi- стандартна помилка коефіцієнта регресії b i .
Оцінка статистичної значущості параметрів та рівняння в цілому – це обов'язкова процедура, яка дозволяє зробити введення про можливість використання побудованого рівняння зв'язку для прийняття управлінських рішень та прогнозування.
Оцінка статистичної значущості рівняння регресії здійснюється з використанням F-критерію Фішера, який є відношенням факторної та залишкових дисперсій, розрахованих на один ступінь свободи.
Факторна дисперсія – пояснена частина варіації ознаки-результату, тобто зумовлена варіацією тих факторів, які включені до аналізу (у рівняння):
де k – число факторів у рівнянні регресії (кількість ступенів свободи факторної дисперсії); - Середнє значення залежної змінної; - теоретичне (розраховане за рівнянням регресії) значення залежної змінної у i – ї одиниці сукупності.
Залишкова дисперсія - непояснена частина варіації ознаки-результату, тобто обумовлена варіацією інших факторів, не включених до аналізу.
 =
=  , (71)
, (71)
де - Фактичне значення залежної змінної у i - ї одиниці сукупності; n-k-1 – число ступенів свободи залишкової дисперсії; n – обсяг сукупності.
Сума факторної та залишкової дисперсій, як зазначалося вище, є загальна дисперсіяознаки-результату.
F-критерія Фішера розраховується за такою формулою:
F-критерій Фішера – величина, що відбиває співвідношення поясненої і непоясненої дисперсій, дозволяє відповісти питанням: чи пояснюють включені у аналіз чинники статистичну значиму частину варіації ознаки-результата. F-критерій Фішера табульований (входом до таблиці є число ступенів свободи факторної та залишкової дисперсій). Якщо  , то рівняння регресії визнається статистично значущим і, відповідно, статистично значущим коефіцієнтом детермінації. Інакше, рівняння – статистично значимо, тобто. не пояснює суттєвої частини варіації ознаки-результату.
, то рівняння регресії визнається статистично значущим і, відповідно, статистично значущим коефіцієнтом детермінації. Інакше, рівняння – статистично значимо, тобто. не пояснює суттєвої частини варіації ознаки-результату.
Оцінка статистичної значущості параметрів рівняння здійснюється на основі t-статистики, яка розраховується як відношення модуля параметрів рівняння регресії до їх стандартних помилок (  ):
):
 , де
, де  ; (73)
; (73)
 , де
, де  . (74)
. (74)
У будь-якій статистичній програмі розрахунок параметрів завжди супроводжується розрахунком значень їх стандартних (середньоквадратичних) помилок та t-статистики. Параметр визнаються статистично значущим, якщо фактичне значення t-статистики більше табличного.
Оцінка параметрів на основі t-статистики, по суті, є перевіркою нульової гіпотези про рівність генеральних параметрів нулю (H 0 : = 0; H 0 : = 0;), тобто про не значущість параметрів рівняння регресії. Рівень значимості прийняття нульових гіпотез = 1-0,95 = 0,05 (0,95 - рівень ймовірності, як правило, що встановлюється в економічних розрахунках). Якщо розрахунковий рівень значимості менше 0,05, то нульова гіпотеза відкидається і приймається альтернативна - статистичної значущості параметра.
Проводячи оцінку статистичної значимості рівняння регресії та її параметрів, ми можемо отримати різне поєднання результатів.
· Рівняння за F-критерієм статистично значуще і всі параметри рівняння з t-статистики теж статистично значущі. Це рівнянняможе бути використано як для прийняття управлінських рішень (на які фактори слід впливати, щоб отримати бажаний результат), так для прогнозування поведінки ознаки-результату при тих чи інших значеннях факторів.
· За F-критерієм рівняння статистично значуще, але незначні окремі параметри рівняння. Рівняння може бути використане для прийняття управлінських рішень (що стосуються тих факторів, якими отримано підтвердження статистичної значущості їх впливу), але рівняння не може бути використане для прогнозування.
· Рівняння за F-критерієм статистично незначне. Рівняння не можна використовувати. Слід продовжити пошук значимих ознак-факторів чи аналітичної форми зв'язку аргументів та відгуку.
Якщо доведено статистична значимість рівняння та її параметрів, може бути реалізований, про, точковий прогноз, тобто. розраховується ймовірне значення ознаки-результату (y) при тих чи інших значеннях факторів (x). Цілком очевидно, що прогнозне значення залежної змінної не співпадатиме з фактичним її значенням. Це пов'язано, перш за все, із суттю кореляційної залежності. Одночасно результат впливає безліч чинників, у тому числі лише частина може бути врахована у рівнянні зв'язку. Крім того, може бути неправильно обрана форма зв'язку результату та факторів (тип рівняння регресії). Між фактичними значеннями ознаки-результату та його теоретичними (прогнозними) значеннями завжди існує відмінність (  ). Графічно ця ситуація виявляється у тому, що не всі точки поля кореляції лежать на лінії регресії. Лише за функціонального зв'язку лінія регресії пройде через усі точки поля кореляції. Різниця між фактичними та теоретичними значеннями результативної ознаки називають відхиленнями чи помилками, чи залишками. На основі цих величин і розраховується залишкова дисперсія, що є оцінкою середньоквадратичної помилки рівняння регресії. Розмір стандартної помилки використовується для розрахунку довірчих інтервалів прогнозного значення ознаки-результату (Y).
). Графічно ця ситуація виявляється у тому, що не всі точки поля кореляції лежать на лінії регресії. Лише за функціонального зв'язку лінія регресії пройде через усі точки поля кореляції. Різниця між фактичними та теоретичними значеннями результативної ознаки називають відхиленнями чи помилками, чи залишками. На основі цих величин і розраховується залишкова дисперсія, що є оцінкою середньоквадратичної помилки рівняння регресії. Розмір стандартної помилки використовується для розрахунку довірчих інтервалів прогнозного значення ознаки-результату (Y).
Для оцінки суттєвості, важливості коефіцієнта кореляції використовується t-критерій Стьюдента.
Знаходиться середня помилка коефіцієнта кореляції за такою формулою:
Н  а основі помилки розраховується t-критерій:
а основі помилки розраховується t-критерій:
Розраховане значення t-критерію порівнюють з табличним, знайденим у таблиці розподілу Стьюдента при рівні значущості 0,05 або 0,01 та числі ступенів свободи n-1. Якщо розрахункове значення t-критерію більше табличного, то коефіцієнт кореляції визнається значним.
При криволінійному зв'язку з метою оцінки значущості кореляційного відношення та рівняння регресії застосовується F-критерій. Він обчислюється за такою формулою:

або 
де - кореляційне відношення; n – кількість спостережень; m – кількість параметрів у рівнянні регресії.
Розраховане значення F порівнюється з табличним для прийнятого рівня значущості (0,05 або 0,01) і чисел ступенів свободи до 1 =m-1 і k 2 =n-m. Якщо розрахункове значення F перевищує табличне, зв'язок визнається суттєвим.
Значимість коефіцієнта регресії встановлюється за допомогою t-критерію Стьюдента, який обчислюється за такою формулою:

де ? 2 а i - Дисперсія коефіцієнта регресії.
Вона обчислюється за такою формулою:

де до - Число факторних ознак в рівнянні регресії.
Коефіцієнт регресії визнається значущим, якщо t a 1 t кр.
t кр перебуває у таблиці критичних точок розподілу Стьюдента при прийнятому рівні значимості та числі ступенів свободи k=n-1.
4.3.Кореляційно-регресійний аналіз в Excel – врожайності зернових культур, у комірки В1: В30 значення результативної ознаки - витрат праці на 1 ц зерна. У меню Сервіс оберемо опцію Аналіз даних. Натиснувши лівою кнопкою миші по цьому пункту, відкриємо інструмент Регресія. Клацаємо по кнопці OK, на екрані з'являється діалогове вікно Регресія. У полі Вхідний інтервал У вводимо значення результативної ознаки (виділяючи комірки В1: В30), у полі Вхідний інтервал Х вводимо значення факторної ознаки (виділяючи комірки А1: А30). Зазначаємо рівень ймовірності 95%, вибираємо Новий робочий лист. Клацаємо по кнопці OK. На робочому аркуші з'являється таблиця «ВИСНОВОК ПІДСУМКІВ», в якій дано результати обчислення параметрів рівняння регресії, коефіцієнта кореляції та інші показники, що дозволяють визначити значущість коефіцієнта кореляції та параметрів рівняння регресії.
|
ВИСНОВОК ПІДСУМКІВ | ||||||||
|
Регресійна статистика | ||||||||
|
Множинний R | ||||||||
|
R-квадрат | ||||||||
|
Нормований R-квадрат | ||||||||
|
Стандартна помилка | ||||||||
|
Спостереження | ||||||||
|
Дисперсійний аналіз | ||||||||
|
Значення F | ||||||||
|
Регресія | ||||||||
|
Коефіцієнти |
Стандартна помилка |
t-статистика |
P-Значення |
Нижні 95% |
Верхні 95% |
Нижні 95,0% |
Верхні 95,0% |
|
|
Y-перетин | ||||||||
|
Змінна X 1 | ||||||||
У цій таблиці «Множинний R» - це коефіцієнт кореляції, «R-квадрат» - коефіцієнт детермінації. "Коефіцієнти: Y-перетин" - вільний член рівняння регресії 2,836242; "Змінна Х1" - коефіцієнт регресії -0,06654. Тут є значення F-критерію Фішера 74,9876, t-критерію Стьюдента 14,18042, « Стандартна помилка 0,112121», які необхідні для оцінки значущості коефіцієнта кореляції, параметрів рівняння регресії та всього рівняння.
За підсумками даних таблиці побудуємо рівняння регресії: у x =2,836-0,067х. Коефіцієнт регресії а 1 =-0,067 означає, що з підвищенням урожайності зернових на 1 ц/га витрати на 1 ц зерна зменшуються на 0,067 чол.-ч.
Коефіцієнт кореляції r=0,85>0,7, отже, зв'язок між ознаками, що вивчаються, в даній сукупності тісний. p align="justify"> Коефіцієнт детермінації r 2 = 0,73 показує, що 73% варіації результативної ознаки (витрат праці на 1 ц зерна) викликано дією факторної ознаки (урожайності зернових).
У таблиці критичних точок розподілу Фішера - Снедекора знайдемо критичне значення F-критерію при рівні значимості 0,05 і числі ступенів свободи до 1 = m-1 = 2-1 = 1 і k 2 = n-m = 30-2 = 28, воно дорівнює 4,21. Оскільки розраховане значення критерію більше табличного (F=74.9896>4,21), рівняння регресії визнається значним.
Для оцінки значущості коефіцієнта кореляції розрахуємо t-критерій Стьюдента:
У  таблиці критичних точок розподілу Стьюдента знайдемо критичне значення t-критерію при рівні значущості 0,05 та числі ступенів свободи n-1 = 30-1 = 29, воно дорівнює 2,0452. Оскільки розрахункове значення більше табличного, то коефіцієнт кореляції є значним.
таблиці критичних точок розподілу Стьюдента знайдемо критичне значення t-критерію при рівні значущості 0,05 та числі ступенів свободи n-1 = 30-1 = 29, воно дорівнює 2,0452. Оскільки розрахункове значення більше табличного, то коефіцієнт кореляції є значним.
Після того як рівняння регресії побудовано та за допомогою коефіцієнта детермінації оцінено його точність, залишається відкритим питанняза рахунок чого досягнуто цієї точності і відповідно чи можна цьому рівнянню довіряти. Справа в тому, що рівняння регресії будувалося не за генеральної сукупності, яка невідома, а щодо вибірки з неї. Крапки з генеральної сукупності потрапляють у вибірку випадковим чином, тому відповідно до теорії ймовірності серед інших випадків можливий варіант, коли вибірка з “широкої” генеральної сукупності виявиться “вузькою” (рис. 15).
Мал. 15. Можливий варіант влучення точок у вибірку з генеральної сукупності.
В цьому випадку:
а) рівняння регресії, побудоване на вибірку, може значно відрізнятися від рівняння регресії для генеральної сукупності, що призведе до помилок прогнозу;
б) коефіцієнт детермінації та інші характеристики точності виявляться невиправдано високими і вводитимуть в оману про прогнозні якості рівняння.
У граничному випадку не виключений варіант, коли з генеральної сукупності хмара з головною віссю паралельної горизонтальної осі (відсутня зв'язок між змінними) за рахунок випадкового відбору буде отримана вибірка, головна вісь якої виявиться нахиленою до осі. Таким чином, спроби прогнозувати чергові значення генеральної сукупності спираючись на дані вибірки з неї загрожують не тільки помилками в оцінці сили та напряму зв'язку між залежною та незалежною змінними, але й небезпекою знайти зв'язок між змінними там, де насправді її немає.
В умовах відсутності інформації про всі точки генеральної сукупності єдиний спосібЗменшити помилки в першому випадку полягає у використанні при оцінці коефіцієнтів рівняння регресії методу, що забезпечує їх незміщеність та ефективність. А ймовірність настання другого випадку може бути значно знижена завдяки тому, що апріорі відома одна властивість генеральної сукупності з двома незалежними один від одного змінними – в ній відсутня саме цей зв'язок. Досягається це зниження з допомогою перевірки статистичної значимості отриманого рівняння регресії.
Один з варіантів перевірки, що найчастіше використовуються, полягає в наступному. Для отриманого рівняння регресії визначається -статистика - характеристика точності рівняння регресії, що є відношенням тієї частини дисперсії залежною змінною яка пояснена рівнянням регресії до непоясненої (залишкової) частини дисперсії. Рівняння для визначення статистики у разі багатовимірної регресії має вигляд:

де: - Пояснена дисперсія - частина дисперсії залежною змінною Y яка пояснена рівнянням регресії;
Залишкова дисперсія - частина дисперсії залежною змінною Y яка не пояснена рівнянням регресії, її наявність є наслідком дії випадкової складової;
Число точок у вибірці;
Число змінних у рівнянні регресії.
Як видно з наведеної формули, дисперсії визначаються як окреме від поділу відповідної суми квадратів на число ступенів свободи. Число ступенів свободи це мінімально необхідне число значень залежної змінної, яких достатньо для отримання шуканої характеристики вибірки і які можуть вільно змінюватись з урахуванням того, що для цієї вибірки відомі всі інші величини, що використовуються для розрахунку потрібної характеристики.
Для отримання залишкової дисперсії потрібні коефіцієнти рівняння регресії. У разі парної лінійної регресії коефіцієнтів два, тому відповідно до формули (беручи ) число ступенів свободи дорівнює . Мається на увазі, що для визначення залишкової дисперсії достатньо знати коефіцієнти рівняння регресії і лише значень залежної змінної вибірки. Два значення, що залишилися, можуть бути обчислені на підставі цих даних, а значить, не є вільно варіюються.
Для обчислення поясненої дисперсії значень залежної змінної взагалі не потрібні, оскільки її можна обчислити, знаючи коефіцієнти регресії при незалежних змінних та дисперсію незалежної змінної. Для того щоб переконатися в цьому, досить згадати вираз, що наводився раніше. ![]() . Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
. Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
В результаті критерій для рівняння парної лінійної регресії визначається за формулою:
 .
.
Теоретично ймовірності доведено, що критерій рівняння регресії, отриманого для вибірки з генеральної сукупності, у якої відсутній зв'язок між залежною і незалежною змінною має розподіл Фішера, досить добре вивчений. Завдяки цьому для будь-якого значення критерію можна розрахувати ймовірність його появи і навпаки, визначити те значення критерію яке він не зможе перевищити із заданою ймовірністю.
Для здійснення статистичної перевірки значущості рівняння регресії формулюється нульова гіпотеза про відсутність зв'язку між змінними (всі коефіцієнти при змінних дорівнюють нулю) і вибирається рівень значущості.
Рівень значущості – це припустима можливість зробити помилку першого роду – відкинути внаслідок перевірки правильну нульову гіпотезу. У даному випадку зробити помилку першого роду означає визнати за вибіркою наявність зв'язку між змінними в генеральній сукупності, коли насправді її там немає.
Зазвичай рівень значущості приймається рівним 5% чи 1%. Що рівень значимості (що менше ), то вище рівень надійності тесту, рівний , тобто. Тим більше шанс уникнути помилки визнання щодо вибірки наявності зв'язку у генеральної сукупності насправді незв'язаних між собою змінних. Але зі зростанням рівня значущості зростає небезпека скоєння помилки другого роду – відкинути правильну нульову гіпотезу, тобто. не помітити за вибіркою наявний насправді зв'язок змінних у генеральній сукупності. Тому залежно від того, яка помилка має великі негативні наслідки, вибирають той чи інший рівень значущості.
Для обраного рівня значущості за розподілом Фішера визначається табличне значення ймовірність перевищення, якого у вибірці потужністю, отриманої з генеральної сукупності без зв'язку між змінними, не перевищує рівня значущості. порівнюється з фактичним значенням критерію для регресійного рівняння.
Якщо виконується умова, то помилкове виявлення зв'язку зі значенням -критерію рівним або більшим за вибіркою з генеральної сукупності з незв'язаними між собою змінними відбуватиметься з ймовірністю меншою за рівень значущості. Відповідно до правила "дуже рідкісних подій не буває", приходимо до висновку, що встановлений за вибіркою зв'язок між змінними є і в генеральній сукупності, з якої вона отримана.
Якщо виявляється , то рівняння регресії статистично не значимо. Іншими словами існує реальна ймовірність того, що за вибіркою встановлено не існує в реальності зв'язок між змінними. До рівняння, що не витримало перевірку на статистичну значущість, ставляться так само, як і до ліків з терміном, що минув термін придатності.
Ті – такі ліки не обов'язково зіпсовані, але якщо немає впевненості у їхній якості, то їх вважають за краще не використовувати. Це правило не вберігає від усіх помилок, але дозволяє уникнути найбільш грубих, що також досить важливо.
Другий варіант перевірки, зручніший у разі використання електронних таблиць, це зіставлення ймовірності появи отриманого значення -критерію з рівнем значущості. Якщо ця можливість виявляється нижче рівня значимості , отже рівняння статистично значуще, інакше немає.
Після того, як виконано перевірку статистичної значущості регресійного рівняння в цілому корисно, особливо для багатовимірних залежностей здійснити перевірку на статистичну значущість отриманих коефіцієнтів регресії. Ідеологія перевірки така ж як і при перевірці рівняння в цілому але як критерій використовується - критерій Стьюдента, що визначається за формулами:
 і
і 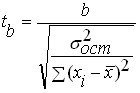
де: - значення критерію Стьюдента для коефіцієнтів і відповідно;
 - Залишкова дисперсія рівняння регресії;
- Залишкова дисперсія рівняння регресії;
Число точок у вибірці;
Число змінних у вибірці, для парної лінійної регресії.
Отримані фактичні значення критерію Стьюдента порівнюються з табличними значеннями ![]() отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
Для змінних, чиї коефіцієнти виявилися статистично не значущими, велика ймовірність того, що їх вплив на залежну змінну в генеральній сукупності взагалі відсутній. Тому або необхідно збільшити кількість точок у вибірці, тоді можливо коефіцієнт стане статистично значущим і заодно уточниться його значення, або як незалежні змінні знайти інші, більш тісно пов'язані з залежною змінною. Точність прогнозування у разі обох випадках зросте.
Як експресний метод оцінки значущості коефіцієнтів рівняння регресії можна застосовувати таке правило - якщо критерій Стьюдента більше 3, то такий коефіцієнт, як правило, виявляється статистично значущим. А взагалі вважається, що для отримання статистично значимих рівнянь регресії необхідно, щоб виконувалася умова.
Стандартна помилка прогнозування щодо отриманого рівняння регресії невідомого значенняпри відомому оцінюють за формулою:

Таким чином, прогноз з довірчою ймовірністю 68% може бути представлений у вигляді:
Якщо потрібна інша довірча ймовірність, то рівня значимості необхідно визначити критерій Стьюдента і довірчий інтервалдля прогнозу з рівнем надійності дорівнюватиме ![]() .
.
Прогнозування багатовимірних та нелінійних залежностей
Якщо прогнозована величина залежить від кількох незалежних змінних, то цьому випадку є багатовимірна регресія виду:
де: - Коефіцієнти регресії, що описують вплив змінних на прогнозовану величину.
Методика визначення коефіцієнтів регресії не відрізняється від парної лінійної регресії, особливо при використанні електронної таблиці, так як там застосовується та сама функція і для парної і для багатовимірної лінійної регресії. У цьому бажано щоб між незалежними змінними були відсутні взаємозв'язки, тобто. зміна однієї змінної не позначалося на значення інших змінних. Але ця вимога не є обов'язковою, важливо щоб між змінними були відсутні функціональні лінійні залежності. Описані вище процедури перевірки статистичної значущості отриманого рівняння регресії та її окремих коефіцієнтів, оцінка точності прогнозування залишається як і для випадку парної лінійної регресії. У той же час застосування багатомірних регресій замість парної зазвичай дозволяє при належному виборі змінних суттєво підвищити точність опису поведінки залежної змінної, а отже, і точність прогнозування.
Крім цього, рівняння багатовимірної лінійної регресії дозволяють описати і нелінійну залежність прогнозованої величини від незалежних змінних. Процедура наведення нелінійного рівняннядо лінійного виду називається лінеаризацією. Зокрема, якщо ця залежність описується поліномом ступеня відмінного від 1, то, здійснивши заміну змінних зі ступенями відмінними від одиниці на нові змінні в першому ступені, отримуємо завдання багатовимірної лінійної регресії замість нелінійної. Так, наприклад, якщо вплив незалежної змінної описується параболою виду
![]()
то заміна дозволяє перетворити нелінійне завдання до багатовимірного лінійного вигляду
![]()
Так само легко можуть бути перетворені нелінійні завдання, у яких нелінійність виникає внаслідок того, що прогнозована величина залежить від твору незалежних змінних. Для обліку такого впливу необхідно запровадити нову змінну, що дорівнює цьому твору.
У тих випадках, коли нелінійність описується складнішими залежностями, лінеаризація можлива за рахунок перетворення координат. Для цього розраховуються значення ![]() та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
перетворюється на лінійну вигляду
Отримані коефіцієнти регресії для перетвореного рівняння залишаються незміщеними та ефективними, але перевірка статистичної значущості рівняння та коефіцієнтів неможлива
Перевірка обґрунтованості застосування методу найменших квадратів
Застосування методу найменших квадратів забезпечує ефективність та несмещенность оцінок коефіцієнтів рівняння регресії за дотримання наступних умов (умов Гауса-Маркова):
3. значення не залежать один від одного
4. значення не залежать від незалежних змінних
Найбільш просто можна перевірити дотримання цих умов шляхом побудови графіків залишків залежно від , Потім від незалежної (незалежних) змінних. Якщо точки на цих графіках розташовані в коридорі розташованому симетрично осі абсцис і розташування точок не проглядаються закономірності, то умови Гауса-Маркова виконані і можливості підвищити точність рівняння регресії відсутні. Якщо це не так, то існує можливість суттєво підвищити точність рівняння і для цього необхідно звернутись до спеціальної літератури.
Підсумкові тести з економетрики
1. Оцінка значущості параметрів рівняння регресії складає основі:
А) t – критерію Стьюдента;
б) F-критерія Фішера - Снедекору;
в) середньої квадратичної помилки;
г) середньої помилки апроксимації.
2. Коефіцієнт регресії у рівнянні , що характеризує зв'язок між обсягом реалізованої продукції (млн. руб.) та прибутком підприємств автомобільної промисловості за рік (млн. руб.) означає, що при збільшенні обсягу реалізованої продукції на 1 млн. руб. прибуток збільшується на:
г) 0,5млн. руб.;
в) 500тис. руб.;
р) 1,5 млн. крб.
3. Кореляційне відношення (індекс кореляції) вимірює ступінь тісноти зв'язку між Х таY:
а) лише за нелінійної форми залежності;
Б) за будь-якої форми залежності;
в) лише за лінійної залежності.
4. У напрямку зв'язку бувають:
а) помірні;
Б) прямі;
в) прямолінійні.
5. За 17 спостереженнями побудовано рівняння регресії:  .
Для перевірки значущості рівняння обчисленоспостережуване значенняt- Статистики: 3.9. Висновок:
.
Для перевірки значущості рівняння обчисленоспостережуване значенняt- Статистики: 3.9. Висновок:
А) Рівняння значимо при a = 0,05;
б) Рівняння незначне за a = 0,01;
в) Рівняння незначне за a = 0,05.
6. Якими є наслідки порушення припущення МНК «математичне очікування регресійних залишківодно нулю»?
А) Зміщені оцінки коефіцієнтів регресії;
б) Ефективні, але неспроможні оцінки коефіцієнтів регресії;
в) неефективні оцінки коефіцієнтів регресії;
г) Неспроможні оцінки коефіцієнтів регресії.
7. Яке з таких тверджень правильне у разі гетероскедастичності залишків?
А) Висновки з t та F-статистиків є ненадійними;
г) Оцінки параметрів рівняння регресії є усунутими.
8. На чому ґрунтується тест рангової кореляціїСпірмена?
А) На використанні t – статистики;
в) На використанні  ;
;
9. На чому базується тест Уайта?
б) На використанні F-статистики;
В) На використанні  ;
;
г) На графічному аналізі залишків.
10. Яким способом можна скористатися для усунення автокореляції?
11. Як називається порушення припущення про сталість дисперсії залишків?
а) мультиколінеарність;
б) автокореляція;
В) Гетероскедастичність;
г) Гомоскедастичність.
12. Фіктивні змінні вводяться у:
а) лише у лінійні моделі;
б) лише у множинну нелінійну регресію;
в) лише у нелінійні моделі;
Г) як у лінійні, так і в нелінійні моделі, що приводяться до лінійного вигляду.
13. Якщо у матриці парних коефіцієнтів кореляції зустрічаються  , то це свідчить:
, то це свідчить:
А) Про наявність мультиколлінеарності;
б) Про відсутність мультиколлінеарності;
в) Про наявність автокореляції;
г) Про відсутність гетероскедастичності.
14. За допомогою якого заходу неможливо позбутися мультиколінеарності?
а) збільшення обсягу вибірки;
Г) Перетворення випадкової складової.
15. Якщо  і ранг матриці А менший (К-1) то рівняння:
і ранг матриці А менший (К-1) то рівняння:
а) надіденцифіковано;
Б) неідентифіковано;
в) точно ідентифіковано.
16.Рівняння регресії має вигляд:
а)  ;
;
б)  ;
;
в)  .
.
17. У чому полягає проблема ідентифікації моделі?
А) одержання однозначно визначених параметрів моделі, заданої системою одночасних рівнянь;
б) вибір та реалізація методів статистичного оцінювання невідомих параметрів моделі за вихідними статистичними даними;
в) перевірка адекватності моделі.
18. Який метод застосовується для оцінювання параметрів надіденцифікованого рівняння?
В) ДМНК, КМНК;
19. Якщо якісна змінна маєkальтернативних значень, то при моделюванні використовуються:
А) (k-1) фіктивна змінна;
б) kфіктивних змінних;
в) (k+1) фіктивна змінна.
20. Аналіз тісноти та напрями зв'язків двох ознак здійснюється на основі:
а) парного коефіцієнта кореляції;
б) коефіцієнт детермінації;
в) множинного коефіцієнта кореляції.
21. У лінійному рівнянні
 x =
а 0
+a 1
x коефіцієнт регресії показує:
x =
а 0
+a 1
x коефіцієнт регресії показує:
а) тісноту зв'язку;
б) частку дисперсії "Y", залежну від "X";
В) на скільки в середньому зміниться "Y" за зміни "X" на одну одиницю;
г) помилку коефіцієнта кореляції.
22. Який показник використовується для визначення частини варіації, обумовленої зміною величини фактора, що вивчається?
а) коефіцієнт варіації;
б) коефіцієнт кореляції;
В) коефіцієнт детермінації;
г) коефіцієнт еластичності.
23. Коефіцієнт еластичності показує:
А) на скільки % зміниться значення y за зміни x на 1 %;
б) на скільки одиниць свого виміру зміниться значення y при зміні x на 1 %;
в) на скільки % зміниться значення y при зміні x на од. свого виміру.
24. Які методи можна застосувати для виявлення гетероскедастичності?
А) Тест Голфелда-Квандта;
Б) Тест рангової кореляції Спірмена;
в) Тест Дарбіна-Вотсона.
25. На чому ґрунтується тест Голфельда-Квандта
а) На використанні t-статистики;
Б) На використанні F – статистики;
в) На використанні  ;
;
г) На графічному аналізі залишків.
26. За допомогою яких методів не можна усунути автокореляцію залишків?
а) узагальненим методом найменших квадратів;
Б) Виваженим шляхом найменших квадратів;
В) Методом максимальної правдоподібності;
Г) Двокроковим методом найменших квадратів.
27. Як називається порушення припущення про незалежність залишків?
а) мультиколінеарність;
Б) автокореляція;
в) Гетероскедастичність;
г) Гомоскедастичність.
28. Яким методом можна скористатися для усунення гетероскедастичності?
А) узагальненим методом найменших квадратів;
б) Виваженим методом найменших квадратів;
в) методом максимальної правдоподібності;
г) Двокроковим методом найменших квадратів.
30. Якщо поt-критерію більшість коефіцієнтів регресії статистично значущі, а модель загалом поF- критерію незначна то це може свідчити про:
а) мультиколінеарності;
Б) Про автокореляцію залишків;
в) Про гетероскедастичність залишків;
г) Такий варіант неможливий.
31. Чи можливо за допомогою перетворення змінних позбавитися мультиколлінеарності?
а) Цей захід ефективний тільки при збільшенні обсягу вибірки;
32. За допомогою якого методу можна визначити оцінки параметра рівняння лінійної регресії:
А) шляхом найменшого квадрата;
б) кореляційно-регресійного аналізу;
в) дисперсійний аналіз.
33. Побудовано множинне лінійне рівняння регресії з фіктивними змінними. Для перевірки значимості окремих коефіцієнтів використовується розподіл:
а) Нормальне;
б) Стьюдента;
в) Пірсон;
г) Фішера-Снідекору.
34. Якщо  і ранг матриці А більший (К-1) то рівняння:
і ранг матриці А більший (К-1) то рівняння:
А) надіденцифіковано;
б) неідентифіковано;
в) точно ідентифіковано.
35. Для оцінювання параметрів точно ідентифікованої системи рівнянь застосовується:
а) ДМНК, КМНК;
б) ДМНК, МНК, КМНК;
36. Критерій Чоу ґрунтується на застосуванні:
А) F – статистики;
б) t – статистики;
в) критерії Дарбіна-Уотсона.
37. Фіктивні змінні можуть набувати значення:
г) будь-які значення.
39. За 20 спостереженнями побудовано рівняння регресії:  .
Для перевірки значущості рівняння обчислено значення статистики:4.2. Висновки:
.
Для перевірки значущості рівняння обчислено значення статистики:4.2. Висновки:
а) Рівняння значимо при a = 0.05;
б) Рівняння незначне при a = 0.05;
в) Рівняння незначне при a = 0.01.
40. Яке з таких тверджень неправильне у разі гетероскедастичності залишків?
а) Висновки з tіF-статистиків є ненадійними;
б) Гетероскедастичність проявляється через низьке значення статистики Дарбіна-Уотсона;
в) При гетероскедастичності оцінки залишаються ефективними;
г) Оцінки є усунутими.
41. Тест Чоу заснований на порівнянні:
а) дисперсій;
б) коефіцієнтів детермінації;
в) математичних очікувань;
г) середніх.
42. Якщо у тесті Чоу  то вважається:
то вважається:
А) що розбиття на подінтервали доцільно з погляду поліпшення якості моделі;
б) модель є статистично незначущою;
в) модель є статистично значущою;
г) що немає сенсу розбивати вибірку на частини.
43. Фіктивні змінні є змінними:
а) якісними;
б) випадковими;
в) кількісними;
г) логічними.
44. Який із перерахованих методів не може бути застосований для виявлення автокореляції?
а) Метод рядів;
б) критерій Дарбіна-Уотсона;
в) тест рангової кореляції Спірмена;
Г) тест Уайт.
45. Найпростіша структурна форма моделі має вигляд:
а) 
б) 
в) 
г)  .
.
46. За допомогою яких заходів можна позбутися мультиколлінеарності?
а) збільшення обсягу вибірки;
б) Винятки змінних висококорельованих з іншими;
в) зміна специфікації моделі;
г) Перетворення випадкової складової.
47. Якщо  і ранг матриці А дорівнює (К-1) то рівняння:
і ранг матриці А дорівнює (К-1) то рівняння:
а) надіденцифіковано;
б) неідентифіковано;
В) точно ідентифіковано;
48. Модель вважається ідентифікованою, якщо:
а) серед рівнянь моделі є хоч одне нормальне;
Б) кожне рівняння системи ідентифікується;
в) серед рівнянь моделі є хоча б одне неідентифіковане;
г) серед рівнянь моделі є хоча б одне надідентифіковане.
49. Який метод застосовується для оцінювання параметрів неіденцифікованого рівняння?
а) ДМНК, КМНК;
б) ДМНК, МНК;
У) параметри такого рівняння не можна оцінити.
50. На стику яких галузей знань виникла економетрика:
а) економічна теорія; економічна та математична статистика;
б) економічна теорія, математична статистика та теорія ймовірності;
в) економічна та математична статистика, теорія ймовірності.
51. У множинному лінійному рівнянні регресії будуються довірчі інтервали для коефіцієнтів регресії за допомогою розподілу:
а) Нормального;
Б) Стьюдента;
в) Пірсон;
г) Фішера-Снідекору.
52. За 16 спостереженнями збудовано парне лінійне рівняння регресії. Дляперевірки значущості коефіцієнта регресії обчисленоt на6л =2.5.
а) Коефіцієнт незначний при a = 0.05;
б) Коефіцієнт значимий при a = 0.05;
в) Коефіцієнт значимий за a=0.01.
53. Відомо, що між величинамиXіYіснуєпозитивний зв'язок. У яких межахперебуває парний коефіцієнт кореляції?
а) від -1 до 0;
б) від 0 до 1;
У) від –1 до 1.
54. Множинний коефіцієнт кореляції дорівнює 0.9. Який відсотокдисперсії результативної ознаки пояснюється впливом усіхфакторні ознаки?
55. Який із перерахованих методів не може бути застосований для виявлення гетероскедастичності?
А) Тест Голфелда-Квандта;
б) Тест рангової кореляції Спірмена;
в) метод рядів.
56. Наведена форма моделі є:
а) систему нелінійних функцій екзогенних змінних від ендогенних;
Б) систему лінійних функційендогенних змінних від екзогенних;
в) систему лінійних функцій екзогенних змінних від ендогенних;
г) систему нормальних рівнянь.
57. У яких межах змінюється приватний коефіцієнт кореляції, обчислений за рекуретними формулами?
а) від -  до +
до +  ;
;
б) від 0 до 1;
в) від 0 до +  ;
;
г) від -1 до +1.
58. У яких межах змінюється приватний коефіцієнт кореляції, обчислений через коефіцієнт детермінації?
а) від -  до +
до +  ;
;
Б) від 0 до 1;
в) від 0 до +  ;
;
г) від -1 до +1.
59. Екзогенні змінні:
а) залежні змінні;
Б) незалежні змінні;
61. При додаванні до рівняння регресії ще одного пояснюючого фактора множинний коефіцієнт кореляції:
а) зменшиться;
б) зросте;
в) збереже своє значення.
62. Побудовано гіперболічне рівняння регресії:Y= a+ b/ X. ДляДля перевірки значущості рівняння використовується розподіл:
а) Нормальне;
Б) Стьюдента;
в) Пірсон;
г) Фішера-Снідекору.
63. Для яких видів систем параметри окремих економетричних рівнянь можна знайти з допомогою традиційного методу найменших квадратів?
а) система нормальних рівнянь;
Б) система незалежних рівнянь;
В) система рекурсивних рівнянь;
г) система взаємозалежних рівнянь.
64. Ендогенні змінні:
А) залежні змінні;
б) незалежні змінні;
в) датовані попередніми моментами часу.
65. У яких межах змінюється коефіцієнт детермінації?
а) від 0 до +  ;
;
б) від -  до +
до +  ;
;
в) від 0 до +1;
г) від -l до +1.
66. Побудовано множинне лінійне рівняння регресії. Для перевірки значимості окремих коефіцієнтів використовується розподіл:
а) Нормальне;
б) Стьюдента;
в) Пірсон;
Г) Фішера-Снідекору.
67. При додаванні до рівняння регресії ще одного пояснюючого фактора коефіцієнт детермінації:
а) зменшиться;
Б) зросте;
в) збереже своє значення;
г) не зменшиться.
68. Суть методу найменших квадратів у тому, что:
А) оцінка визначається за умови мінімізації суми квадратів відхилень вибіркових даних від оцінки, що визначається;
б) оцінка визначається за умови мінімізації суми відхилень вибіркових даних від оцінки, що визначається;
в) оцінка визначається за умови мінімізації суми квадратів відхилень вибіркової середньої від вибіркової дисперсії.
69. До якого класу нелінійних регресій належить парабола:
73. До якого класу нелінійних регресій відноситься експоненційна крива:
74. До якого класу нелінійних регресій належить функція виду ŷ  :
:
А) регресії, нелінійні щодо включених до аналізу змінних, але лінійних за оцінюваними параметрами;
б) нелінійні регресії за оцінюваними параметрами.
78. До якого класу нелінійних регресій відноситься функція виду ŷ  :
:
а) регресії, нелінійні щодо включених до аналізу змінних, але лінійних за оцінюваними параметрами;
Б) нелінійні регресії за оцінюваними параметрами.
79. У рівнянні регресії у формі гіперболи ŷ  якщо величинаb
>0
, то:
якщо величинаb
>0
, то:
а) зі збільшенням факторного ознаки хзначення результативної ознаки ууповільнено зменшуються, і при х→∞середня величина убуде рівна а;
б) то значення результативної ознаки узростає із уповільненим зростанням зі збільшенням факторного ознаки х, і при х→∞

81. Коефіцієнт еластичності визначається за формулою 
а) лінійної функції;
б) Параболи;
в) гіперболи;
г) Показовою кривою;
д) Ступінневої.
82. Коефіцієнт еластичності визначається за формулою  для моделі регресії у формі:
для моделі регресії у формі:
а) лінійної функції;
Б) Параболи;
в) гіперболи;
г) Показовою кривою;
д) Ступінневої.
86. Рівняння  називається:
називається:
а) лінійним трендом;
б) параболічним трендом;
в) гіперболічний тренд;
г) експоненційним трендом.
89. Рівняння  називається:
називається:
а) лінійним трендом;
б) параболічним трендом;
в) гіперболічний тренд;
г) експоненційним трендом.
90. Система види
 називається:
називається:
а) системою незалежних рівнянь;
б) системою рекурсивних рівнянь;
в) системою взаємозалежних (спільних, одночасних) рівнянь.
93. Економетрику можна визначити як:
А) це самостійна наукова дисципліна, що об'єднує сукупність теоретичних результатів, прийомів, методів та моделей, призначених для того, щоб на базі економічної теорії, економічної статистики та математико-статистичного інструментарію надавати конкретний кількісний вираз загальним (якісним) закономірностям, зумовленим економічною теорією;
Б) наука про економічні виміри;
У) статистичний аналіз економічних даних.
94. До завдань економетрики можна віднести:
А) прогноз економічних та соціально-економічних показників, що характеризують стан та розвиток аналізованої системи;
Б) імітація можливих сценаріїв соціально-економічного розвитку системи для виявлення того, як плановані зміни тих чи інших параметрів, що піддаються управлінню, позначаться на вихідних характеристиках;
в) перевірка гіпотез за статистичними даними.
95. За характером розрізняють зв'язки:
А) функціональні та кореляційні;
б) функціональні, криволінійні та прямолінійні;
в) кореляційні та зворотні;
г) статистичні та прямі.
96. При прямому зв'язку із збільшенням факторної ознаки:
а) результативна ознака зменшується;
б) результативна ознака не змінюється;
В) результативна ознака зростає.
97. Які методи використовуються для виявлення наявності, характеру та напряму зв'язку у статистиці?
а) середніх величин;
Б) порівняння паралельних рядів;
В) метод аналітичного угруповання;
г) відносних величин;
д) графічний метод.
98. Який метод використовується виявлення форми впливу одних чинників інші?
а) кореляційний аналіз;
Б) регресійний аналіз;
в) індексний аналіз;
г) дисперсійний аналіз.
99. Який метод використовується для кількісної оцінки сили впливу одних факторів на інші:
а) кореляційний аналіз;
б) регресійний аналіз;
в) метод середніх величин;
г) дисперсійний аналіз.
100. Які показники за своєю величиною існують у межах від мінус до плюс одиниці:
а) коефіцієнт детермінації;
б) кореляційне ставлення;
У) лінійний коефіцієнт кореляції.
101. Коефіцієнт регресії при однофакторній моделі показує:
А) скільки одиниць змінюється функція при зміні аргументу однією одиницю;
б) скільки відсотків змінюється функція однією одиницю зміни аргументу.
102. Коефіцієнт еластичності показує:
а) на скільки відсотків змінюється функція зі зміною аргументу одну одиницю свого виміру;
Б) на скільки відсотків змінюється функція із зміною аргументу на 1%;
в) скільки одиниць свого виміру змінюється функція зі зміною аргументу на 1%.
105. Розмір індексу кореляції, що дорівнює 0,087, свідчить:
А) про слабку їхню залежність;
б) про сильний взаємозв'язок;
в) про помилки у обчисленнях.
107. Розмір парного коефіцієнта кореляції, що дорівнює 1,12, свідчить:
а) про слабку їхню залежність;
б) про сильний взаємозв'язок;
В) про помилки у обчисленнях.
109. Які із наведених чисел можуть бути значеннями парного коефіцієнта кореляції:
111. Які із наведених чисел можуть бути значеннями множинного коефіцієнта кореляції:
115. Позначте правильну форму лінійного рівняння регресії:
а) ŷ  ;
;
б) ŷ  ;
;
в) ŷ  ;
;
Г) ŷ  .
.